CRAN is one of the many things that makes R such a great language. For those that don’t know, it’s where R users get the vast majority of the add-on packages that they use with the core language. CRAN also hosts downloads of the language itself, source code, tools and so on, but it’s most well known among users as the place where all the packages come from.
The “CRAN team” are responsible for the ongoing maintenance of CRAN, handle new and updated package submissions and generally ensure everything is running smoothly. The CRAN team do an excellent job maintaining the complex set of systems and process that make up the service that the community often doesn’t think much about at all. In this post though, I want to look at CRAN in terms of how it works for the installation of packages for us as end users. The goal is to understand it well enough to build your own CRAN-like system, though that will likely come in a future post.
What’s under the hood?
The package repository part of CRAN is comprised of four main pieces:
- A web server
- A specific directory layout
- Some PACKAGES files (more on these later!)
- R packages
Hopefully the “R packages” part is fairly self explanatory, so we’ll look at each of the the other parts in turn.
The web server
This is what makes CRAN available on the internet. It’s responsible for dealing with requests from R for packages. In the case of the real CRAN, it’s also what serves up the pages that you might view when you visit the website.
CRAN has a global network of ‘mirror’ servers that are all running different web server software, so there isn’t really a standard here. People are free to use whatever web server they want. Some popular examples include: Apache httpd, nginx and IIS. There’s also a small web server built right into python (http.server) and R itself has packages like servr, which perform the same function.
The directory layout
When R goes to CRAN to get packages, it expects to find them in specific places. If it doesn’t find what it’s looking for installation will fail. To make this work it uses a very specific directory layout.
Here’s a really minimal directory layout to illustrate the idea:
cranroot
|-- bin
| |-- macosx
| | `-- el-capitan
| | `-- contrib
| | `-- 3.5
| `-- windows
| `-- contrib
| `-- 3.5
`-- src
`-- contrib
In this example, ‘cranroot’ could be any directory, it just signifies the root of the directory layout. Inside that we have ‘bin’ and ‘src’, for binaries and source code respectively. The ‘contrib’ directories are where the contributed software, R packages, live (in the case of binaries, inside sub-directories named for the R version).
As you might expect, the actual CRAN has a great many more directories, but these are the important ones for us at the moment. If you want to see how all this looks on the real CRAN, check out the ‘bin’ and ‘src’ directories and have a browse around.
PACKAGES files
Each ‘contrib’ or contrib sub-directory (eg 3.4, 3.5, 3.6 etc.) has a PACKAGES file in it. This file is like an index or manifest of the packages available within the repository. It contains information pulled from each package’s description file in plain text DCF (Debian Control File) format. (Now you know why R has a read.dcf() function!)
PACKAGES files come in three flavours. There’s plain PACKAGES, which is the DCF file mentioned above. There’s PACKAGES.gz, which is the plain version but gzipped. Lastly, there’s PACKAGES.rds which contains the same information, but serialised using R’s RDS format.
Installing a package
When you install a package, R does a few things. First, it gets the ‘src/contrib/PACKAGES.rds’ file. Then, using information about your OS version and R version it tries to get PACKAGES.rds for the appropriate binaries for your system. In my case, the path for this is ‘bin/el-capitan/PACKAGES.rds’.
Note: I’m actually running MacOS 10.14 (code name: Mojave), not ‘El Capitan’, which was version 10.11. I’m not sure how the CRAN team figure this stuff out. Perhaps El Capitan was the last time the build tool-chain (compilers and so on) changed significantly, I’m not sure.
Anyway, when I ran this earlier today that particular PACKAGES.rds wasn’t available, so R does the smart thing and falls back on PACKAGES.gz.
At this point, R has the PACKAGES data for both the source and binary packages. It can use this to see if the source version is newer. This is why you sometimes get those pop-ups in RStudio, telling you the source version is newer and asking if you’d like to install that instead.
If the available binary package is not older than the available source package, R will figure out the depenendcies and download the required packages for you.
I recorded my traffic from R to CRAN while I ran the following:
install.packages("mangoTraining",
repos = "http://cran.rstudio.com")
The ‘mangoTraining’ package is a nice simple example as it has no dependencies and I intentionally used the ‘http’ version of RStudio’s CRAN mirror to make recording my traffic easier. You should always use ‘https’ versions where possible.
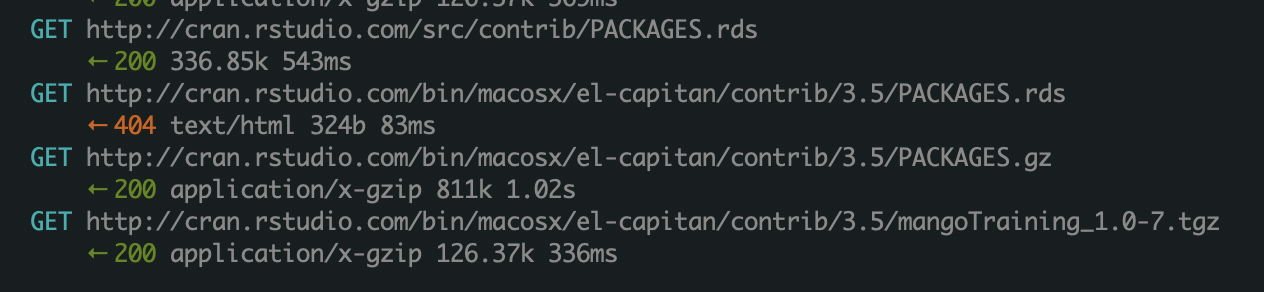
Notice the 404 (resource not found) error in the output above. That’s the web server telling R that the thing it requested, ‘bin/macosx/el-capitan/contrib/3.5/PACKAGES.rds’, is not available and the following request is R falling back on the gzipped version instead, before finally downloading the package.
Wrapping up
In this post we’ve looked at how CRAN works from the perspective of hosting packages for us to install from within R. The system itself is almost ingeniously straightforward. It’s built from some fairly standard building blocks like a directory tree and a web server. The PACKAGES file is obviously specific to R, but even that plain text (or an RDS version of the same data). In the next post we’ll look at building our own CRAN to further explore how all these pieces fit together.