In my last post, “Lifting the lid on CRAN”, we took a look at how R and CRAN interact to enable R users to install packages. In this post we’re going to dig a little deeper by building our own CRAN-like repo that we can install packages from.
Enterprise R package management
Before we get started, I just want to stress that what we’ll learn about here is no substitute for using a product like RStudio Package Manager. RSPM is an enterprise ready R package management solution with all sorts of useful extra features like building packages from git repos, serving up internal packages or curated sub-sets of CRAN, or indeed acting as a proxy for the full CRAN. It’s a fantastic tool for enterprise R users and you can read more about it on the RStudio website. Recent versions of JFrog’s “Artifactory” also support CRAN-like repositories and CRAN proxying.
Getting started
In the previous post we saw that CRAN is comprised of four main components:
- A web server
- A specific directory layout
- PACKAGES files
- Some packages!
We’re going to build a minimally workable CRAN-like repository that we can install packages from using these components. For our example we’re going to build a repository that contains a small subset of the complete CRAN. We’ll host it on the same system that we’re using R on, though if you wanted to do something more permanent, it’d work just as well on a server of some sort.
Creating the directory layout
There are three main types of packages that CRAN serves up to end users: Windows binaries, Mac binaries and source packages.
The source packages are used to create the Mac and Windows binaries, but they’re also used as-is to install packages on Linux platforms. In general on Linux, all packages that you install using install.packages() will be built from the source code during installation. In fact, R on Linux could install binary versions of packages but CRAN does not make them available, so source must be used instead.
It’s also possible to install the source versions of packages on Mac and Windows if you have the correct build tools installed. To keep things simple and to make sure they work across all the different operating systems, I’ll be walking through building our CRAN-like repository using the source packages only. This means MacOS and Windows users in particular will need to ensure they have the tools required to build packages installed on their system. Check CRAN if you’re unsure what you need.
Choose a directory to build our CRAN repo inside. I’m calling mine ‘cranroot’. Inside, we need to create a directory called ‘src’ and another one inside that called ‘contrib’. As we’re only going to be hosting source packages that’s all the directory structure we’ll need. You should end up with a series of three directories like this: cranroot/src/contrib.
dir.create("cranroot/src/contrib", recursive = TRUE)
Getting some packages to host
As we want to host a small subset of the full CRAN we need to choose what we’ll host so that we can download the source versions of those packages.
I’ve decided to use the excellent “tidytext” package from Julia Silge and David Robinson as the basis for this. As you might have guessed, tidytext on its own won’t be enough. We’ll also need its dependencies. Fortunately R’s “tools” package has a useful function, package_dependencies(), that we can use to discover what they are:
local({r <- getOption("repos")
r["CRAN"] <- "http://cran.rstudio.com"
options(repos=r)
})
tools::package_dependencies("tidytext")
The package_dependencies() function is actually using the PACKAGES file from your default CRAN mirror to work out what the dependencies are.
Even this list is not enough for our purposes though as we need the dependencies of the dependencies! In fact, we need all the packages from the complete dependency tree. Luckily, we can use the ‘recursive’ parameter to get just that:
tools::package_dependencies("tidytext",
recursive = TRUE)
Now that we know what packages we need to download, we can go ahead and download them:
pkg_deps <- tools::package_dependencies("tidytext",
recursive = TRUE)
# add "tidytext" to the list
pkgs <- c(pkg_deps$tidytext, "tidytext")
download.packages(pkgs = pkgs,
destdir = "cranroot/src/contrib",
type = "source")
This will download all the dependencies except those that are part of base R, which it will skip.
You can then have a look inside the directory just to make sure everything is there.
If you were doing this for yourself, you could use whatever packages you wanted, including your own. We’re doing it this way to demonstrate the principles rather than anything else. The rest of the process remains the same, regardless of where you get your packages sources from.
Create the PACKAGES files
We’re almost finished now. The next step is to create the PACKAGES files that R uses to figure out what packages are available in the repository. Luckily, the tools package comes to the rescue again, this time with the write_PACKAGES() function.
tools::write_PACKAGES(dir = "cranroot/src/contrib",
type = "source")
When we check the directory afterwards we should have three different versions of the file: the plain PACKAGES, the gzipped version and the RDS version.

Starting a web server
The final step in creating our own CRAN is to start up a web server so that we can install packages from it. As we’re just experimenting at the moment, we’re going to use the “servr” package to serve up our CRAN-like repo.
servr::httd("cranroot")
This will start a web server and also launch a browser session so that you can examine what you’ve built. Click through the “src” directory and into “contrib” where you should see something similar to this:
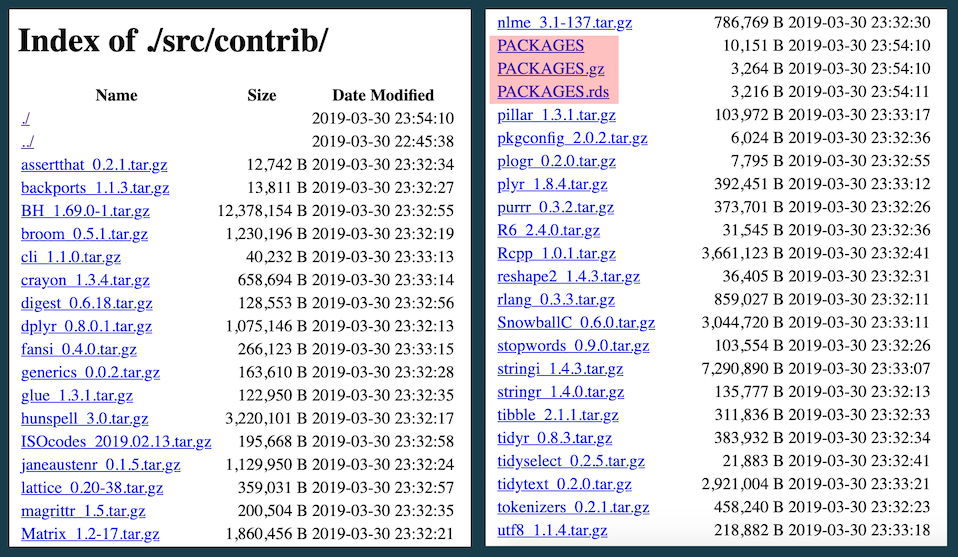
I’ve highlighted the three PACKAGES files that we just created.
Note: Using servr in our current session is fine for experimentation, but if I were hosting a personal CRAN like this on a server I’d use a dedicated piece of web server software like “nginx”.
Using our new CRAN repo
We’re now ready to try to use our new CRAN-like repository. When we ran the servr::httd() function a moment ago, you will hopefully have noticed some output that ended with a URL like “http://127.0.0.1:4321”.
This is the URL of the CRAN-like package repository that we’ve built and we can plug this directly into install.packages(), like this:
install.packages("tidytext",
repos = "http://127.0.0.1:4321",
type = "source")
Assuming your system is set up properly for building packages from source, the packages will be downloaded, built and installed. Since we are building from source this process will take longer than just installing binary versions, but the end result is the same. The repository could conceivably be used by Mac, Windows and Linux users in exactly the same way too.
Updates and maintenance
The biggest drawback with creating a repository in this way is in maintaining it. How do you handle package updates? How often should packages be updated? Would you archive old versions as CRAN does? How do you ensure your code, old and new, will work against this system now and into the future?
None of these things are insurmountable, of course, but they’re enough of a barrier to make a commercial tool like RStudio Package Manager look very appealing since it handles everything for you.
There are also packages like “miniCRAN” that put a nice wrapper around a lot of this stuff, but it still needs someone to look after it all.
Wrapping up
I hope you’ve enjoyed this little look at how CRAN works and have enjoyed experimenting with building your own. It’s interesting to get an insight into the work that goes into maintaining the real CRAN, with it’s ~14,000 packages. It’s hopefully also useful to understand how you might go about building your own. It’s a great way to experiment with the tools and get a deeper insight into how the R-CRAN relationship works when installing or updating packages.
As ever, if you have any questions or feedback, let me know.