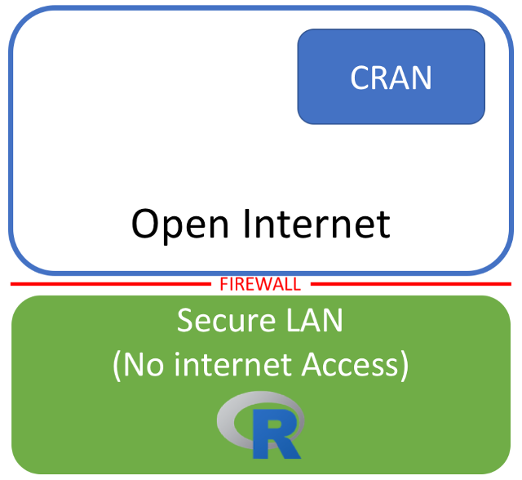
If you were in an environment where you have R running on server on a secure LAN with no internet access, you’ll be familiar with the situation outlined in the image above. R is running in an environmnet where there is no internet access, and you’re therefore unable to install anything from CRAN. This is common in many large organisations where the security of the systems is more important than end user convenience.
In general in these sorts of situations, packages must be downloaded manualy and and installed. This in turn can lead to the bane of any manual installation, the “dependency dance” where you try to install a package, only to discover that there’s a dependency you hadn’t considered, which you must then download and install manually as well. If that dependency has dependencies of its own, congratulations, you’re now doin the dependency dance! This is a particularly painful situation, particularly if there are many machines that require additional packages.
There are many ways to approach this problem. You could obtain a packaged version of R with the dependencies you need. You could build your own internal CRAN-like repository. You could use R in docker containers, with the packages you need baked in. One approach that I’ve found success with is to obtain permission from corporate security to build a reverse proxy, or accelerator, like Squid inside the firewall that is permitted to connect to CRAN (and CRAN alone).
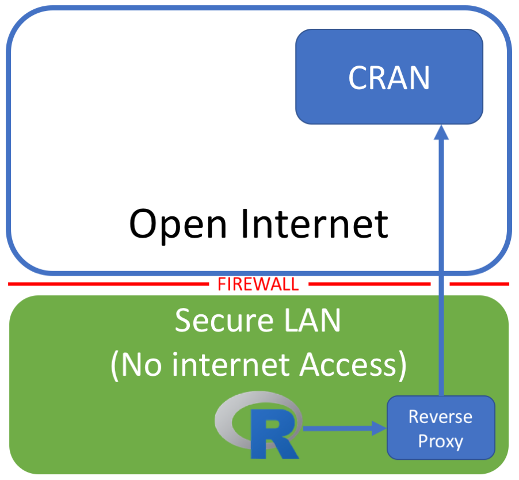
The proxy behaves exactly as though it were CRAN, but inside your organisations firewall. Request sent to the proxy machine are passed on to CRAN behind the scenes and returned as normal. The result is effectively the same as using the real CRAN and packages can be installed by either specifying the proxy system as a repo:
install.packages("ggplot2", repos = c("https://cranproxy.local"))
Or by setting the proxy as the default CRAN repo to use.
Obviously this approach still requires making a hole in your firewall to the outside world, but it’s a single hole, not one for each machine running R, so it’s easier to get corporate security to sign off on it.
Interestingly, there are other benefits too. Firstly, a proxy like squid was designed to cache requests. This means that if you ask for the same thing twice, the second one will come from the cache rather than directly from CRAN. Which in turn means that the second result should be returned faster, as the result is coming from within your own network, not outside of it. This speeds up installs, reduces your network usage, and lightens the load on the CRAN mirror you’re proxying and can be really useful if you’re managing lots of systems. A further benefit, is that you’ll have access to the proxy logs, which means you’ll be able to do some simple analyses on things like the most popular packages within your organisation. This can obviously be useful to use therefore, even with desktop users in a corporate environmnet.
Naturally, if you’re going to be proxying requests to CRAN in this way, you’ll want to make sure you choose a local mirror and configure the proxy to work with it accordingly. Further information on squid proxy/accelerator configuration can be found here.