I started the awesome blogdown list not long after I first heard about the blogdown package for R. I wanted a quick and easy way to showcase websites built with it, so I started a simple “awesome” style README page on GitHub.
This was OK for a little while, but it soon started to bug me that the same sites were at the top. The top of the list is prime real estate, especially for the casual visitor who might just skim the first few entries before decided where to go next, so having some mechanism for rotating what’s presented there seemed like a good idea.
I wanted to move away from the static list to aid in discovery of new blogdown blogs, so I turned the github README into a website. I bought awesome-blogdown.com and built a website that randomised the order of the list each time the page loaded. Now the prime places near the top of the list were open to everyone.
This was done by turning the list into a JSON file that gets served to your browser along with the site itself. Some JavaScript in the page parses the JSON, randomises the order of the elements and then builds the table that the user sees.
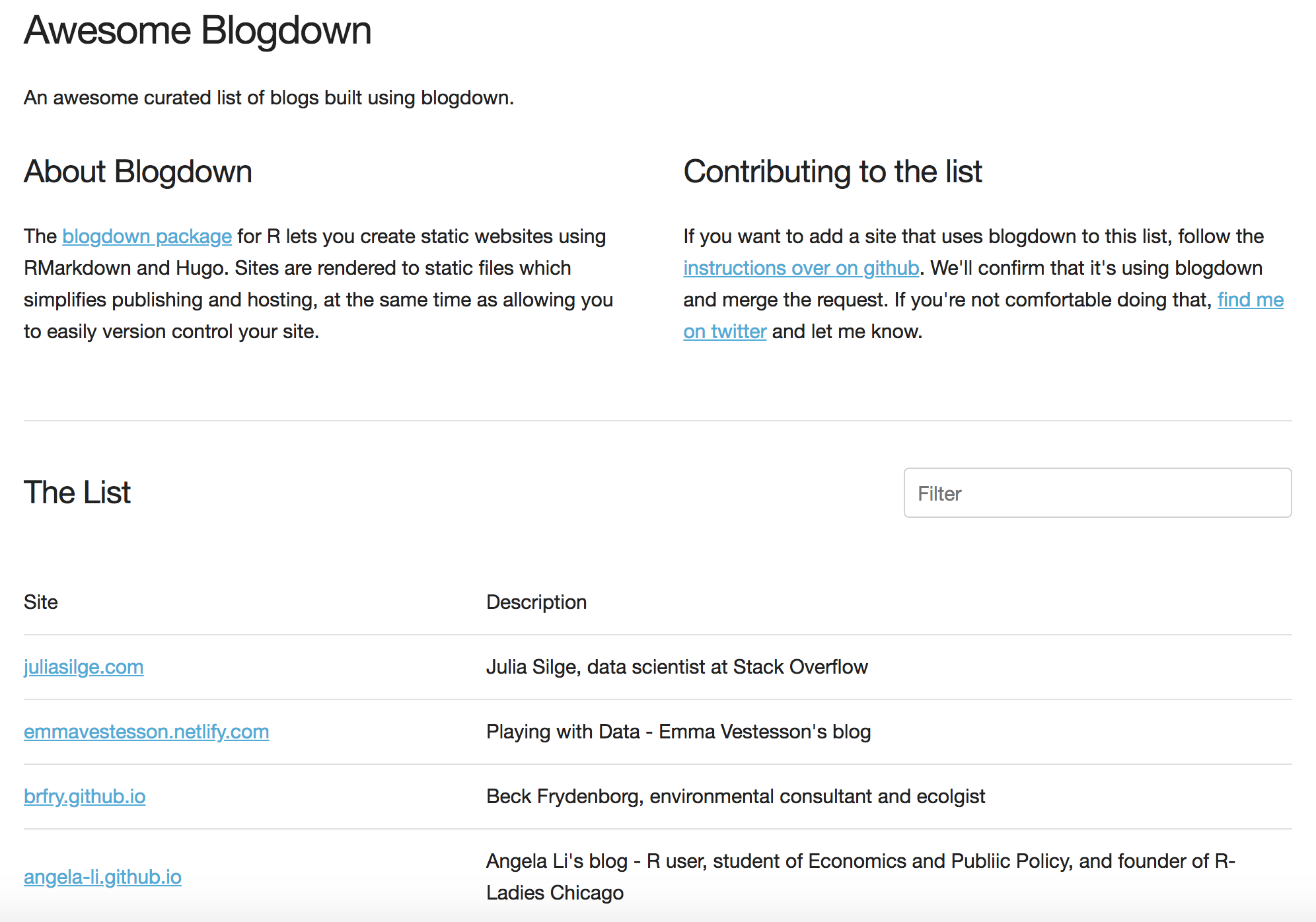
The website is still in the same GitHub repo where the project started, but now the website components (html, CSS, JavaScript and JSON) get deployed to Netlify where the site is hosted. I originally did that because hosting on GitHub pages didn’t support HTTPS, though I understand that it does now. That deployment is entirely automatic and happens when new code is pushed to a specific branch.
Having the list appear in a random order is a good start, but it would be useful to have some sort of search feature, right? My JavaScript skills are rudimentary at best, so I wasn’t going to start anything from scratch, but I remembered seeing a cool “filter” feature on Jessie Frazelle’s Docker repo site and managed to adapt it for Awesome Blogdown.
By this time, storing all the sites in a single JSON file was starting to cause me a few headaches. Whilst JSON is human-readable, it’s usually best if we leave writing it to machines, especially with larger files. I was asking people to add their site to the bottom of a long JSON file and submit a pull request. The vast majority of the time, this worked fine, but occasionally (and at least twice myself!) someone would miss a comma out or something and invalidate the JSON. If I didn’t spot it and merged the pull request, we now had broken JSON in the repo. Netlify don’t know that I broke the JSON though, so it was being deployed to the live site automatically, where the JSON issue usually stopped the list from displaying at all.
To fix this, I decided to use Travis-CI, the continuous integration platform. Travis can be configured to do lots of interesting things, but in this case I wanted it to test the validity of the JSON. This way, new pull requests will get tested automatically, so the author of the pull request will see there’s been an issue and correct it. I could have written some sort of JSON checking tool in R or python, but there’s a really great command line utility called ‘jq’ that does the job just fine. I just wrapped it in a tiny shell script and configured Travis to run it.
#!/usr/bin/env bash
set -euo pipefail
INFILE=${1:-"missing"}
if [[ ${INFILE} == "missing" ]]; then
echo "Usage: $(basename ${0}) <input file>"
exit 1
fi
cat ${INFILE} | jq '' >/dev/null
if [[ $? -eq 0 ]]; then
echo "$(date +%D-%T) - json validity check - PASS"
exit 0
else
echo "$(date +%D-%T) - json validity check - FAIL"
exit 1
fi
The other big problem at the time was that since all new sites go at the bottom of the file, if two people create pull requests at more or less the same time, I could only merge one of them and the other would result in a merge conflict since there’s new stuff in the way of the second one. This seemed like a harder problem to solve, but I eventually opted for breaking the large JSON file into lots of smaller ones, with one for each site. Since the site itself runs off the one large JSON file, I needed a way to join all these small files together to create the larger one, while maintaining the validity of the JSON. Again, Travis and jq come to the rescue here, no need to write something from scratch, just another quick shell script wrapper around jq and we’re nearly done.
#!/usr/bin/env bash
set -euo pipefail
INPUTDIR=${1:-"missing"}
OUTFILE=${2:-"missing"}
if [[ ${INPUTDIR} == "missing" ]] || [[ ${OUTFILE} == "missing" ]]; then
echo "Usage: $(basename ${0}) <input file dir> <output file>"
exit 1
fi
jq . -c -s ${INPUTDIR}/*.json > ${OUTFILE}
Both of these scripts are run by ‘make’ using the Makefile in the github repo. If the JSON validity check and the building of the large JSON file both succeed then Travis is configured to push the large file back into the branch of the git repo that contains the website code and then Netlify does its magic and publishes the changed list.

In terms of how the project has evolved, that already feels like a lot, but it doesn’t stop there. I recently realised that occasionally a given URL will go dark. Maybe the author decided they didn’t want to run a blog after all, or maybe they moved it to a new URL and forgot to update awesome-blogdown with the new URL. Whatever the reason, I needed a way to check for these changes. There’s nothing worse than going to a site and discovering a load of broken links. It’s the sort of thing that stops people coming back a second time.
I needed a way to report on the status of the URLs. I could probably have used a tool like linkchecker (which I’ve already built a docker container for), but I hadn’t written any code for a while, so I decided to try to solve this one myself. Foolishly I started out, as I often do, trying to solve the problem in bash. The core of bash is extremely robust, but it’s most often used to glue a load of non-bash command line utilities together, which can cause problems especially with larger projects, so I decided to try again in python and quickly had a script that will check that each site on awesome-blogdown.com returns a non-error HTTP status code, for instance ‘200 OK’.
Now I have a site checking script that works, which is driven from the same JSON file as the site itself, but how do I make it run? I could use Travis again, since that supports running code on a schedule, but I decided to use my own private Jenkins server instead. For those of you unfamiliar with Jenkins, it’s a bit like Travis-CI, but you host it yourself, in my case in a cupboard under the stairs! In order to ensure that the script runs consistently every time, I wanted to use docker to package it up.
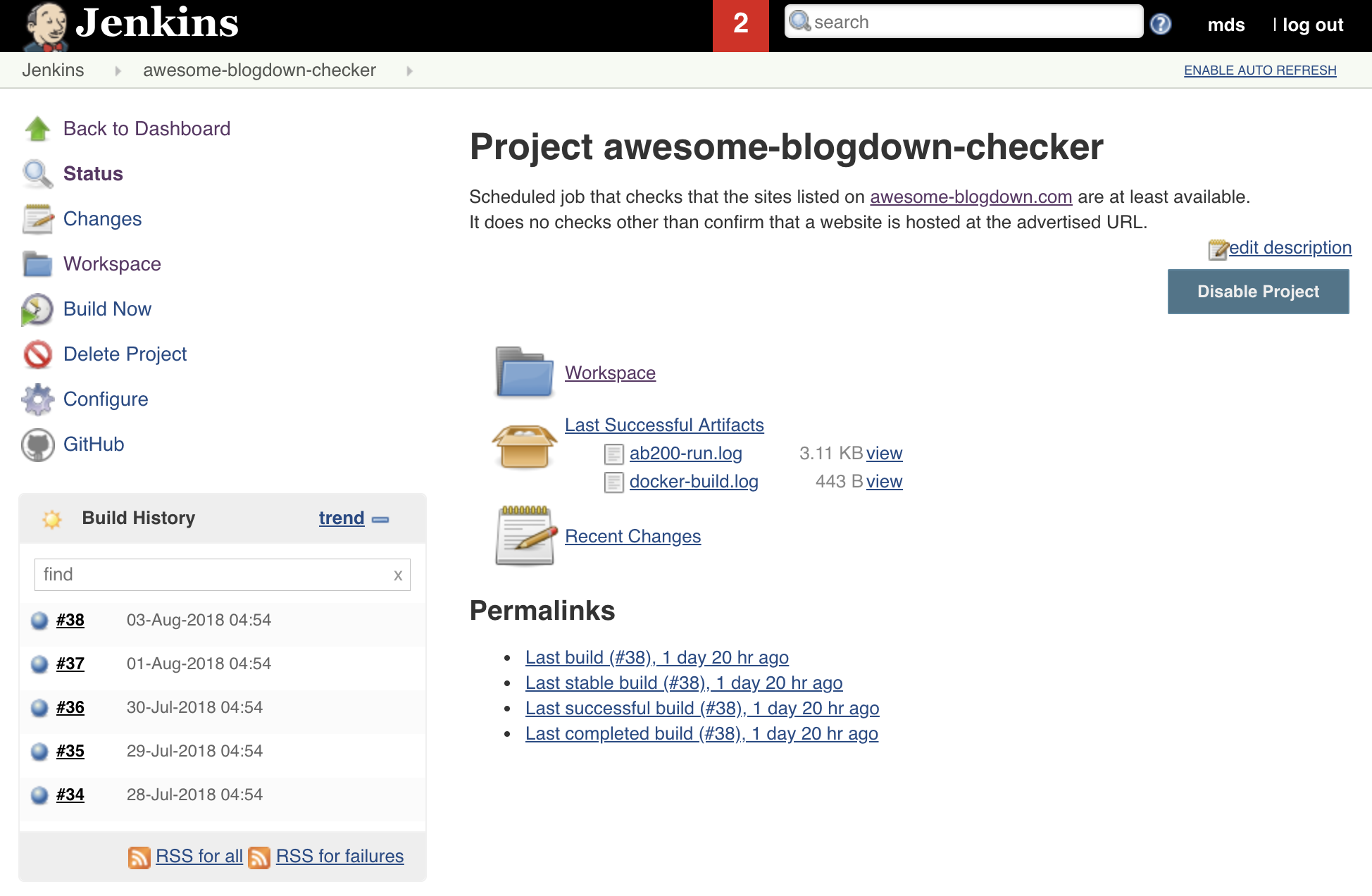
If you’ve not checked out docker yet and you have the time, you absolutely should, it’s a great way to package up your code and dependencies in a way that’s both portable and reproducible. So at this point I wrote another Makefile, which in turn uses a Dockerfile to build a docker image with my checker script and python, and the additional package the script uses. The Makefile then goes on to run the docker image. This is run on a schedule in Jenkins, so it runs three times a week, just checking to make sure the site is still there, nothing else.
Running this script in Jenkins means I have to go and look at Jenkins three times a week to see how things are doing though, which is clearly unacceptable for someone like me, who likes to automate things. The last piece of the puzzle (for now 😉) is to have some way of reporting the results of the check back to me. Slack seemed like a natural fit since I use it on all my devices, so I used the Slack webhook integration to have the script report back the results to me.

Even for a small static site like Awesome Blogdown there can be many moving parts in the background, so I hope you’ve enjoyed this little tour of what’s gone in to making it tick. All the code and config and pretty much everything I’ve mentioned in this post is available in the GitHub repo. If you’re an R user, do check out the blogdown package, and if you decide to make a blog with it, be sure to submit a pull request for awesome blogdown as well!