
What are git hooks?
From githooks.com
Git hooks are scripts that Git executes before or after events such as: commit, push, and receive. Git hooks are a built-in feature - no need to download anything.
They’re basically bits of code that are triggered by a particular git event. The code can do anything you like. For instance you could use the ‘pre-push’ hook to trigger some code immediately prior to a git push. This could be used to test something, or post a message to slack saying: “Mark’s just pushed some code - Prepare for a broken build!”
If your code exits cleanly (with a 0 exit code) then the specified action – such as the git push – proceeds. If the code produces an error (any non-zero exit code), then the specified action is not run and the output of your code is displayed.
The sorts of git hooks that we’re discussing here are all run locally on the system you’re working on. This detail will become very important later on.
Our example problem
One of my spare-time projects is an R package called memorids. It’s a pretty silly package by most measures. It only has a single function and that function just outputs a random adjective and noun combo, like ‘unshaved-oven’.
Whilst the package itself is very simple, the scaffolding around the package – particularly around the management of the adjective and noun lists – is much more substantial.
The adjective and noun lists are just plain text files which are then used to create a R/sysdata.rda binary file. The source files and the sysdata file all live in the repo. I’m not a huge fan of keeping binary objects that are updated regularly in source control, but without it I don’t think the package could be installed using the devtools::install_github() approach.
Note: The adjective and noun lists were built using both manual addition and web scraping approaches (rvest for the win!). The full contents of both lists are currently under review, but if you spot anything in either list that you think shouldn’t be there, please let me know.
In order to make this work I have a Makefile and a couple of scripts in the ‘data-raw’ directory that create the sysdata file from the ‘adjectives.txt’ and ’nouns.txt` files.
For the most part, this works pretty well, but I found myself frequently forgetting to update the sysdata file before committing new versions of the adjectives and nouns lists. The means the sysdata file becomes out of sync with the source files. This in itself isn’t catastrophic, I could just rebuild the sysdata file and push a new commit to the repo, but it was annoying me enough to want to do something about it.
Enter the ‘pre-commit’ hook. As the name suggests, this hook is run immediately prior to a git commit. Once set up this is completely transparent to the user. You run git commit just as you normally would, but git executes your pre-commit hook before going on to perform the requested commit.
First version, using bash
In this case we want a pre-commit hook that will prevent me from committing to the repo if the sysdata file is older than either of the adjectives.txt or nouns.txt source files.
I’ve been writing scripts in bash since long before I learnt any R or Python, so I’m pretty comfortable doing system things like this with it.
#!/usr/bin/env bash
# make sure that R/sysdata.rda is not out of date
STATUS=0
if [[ $(stat -c '%Y' ./data-raw/nouns.txt) > $(stat -c '%Y' ./R/sysdata.rda) ]]; then
echo "nouns.txt is newer than sysdata.rda - run 'make' in ./data-raw"
STATUS=1
fi
if [[ $(stat -c '%Y' ./data-raw/adjectives.txt) > $(stat -c '%Y' ./R/sysdata.rda) ]]; then
echo "adjectives.txt is newer than sysdata.rda - run 'make' in ./data-raw"
STATUS=1
fi
exit ${STATUS}
Hopefully, even if you don’t know bash, you can still pick your way through. The important bit is stat -c '%Y' /path/to/file. This returns the file’s last modified date in ‘Unix time’. Unix time stamps are easier to work with in bash as they’re just integers. The script compares the the time stamps of the source files to the sysdata file and then either exits with a 0, indicating no problems found, or prints some messages about the error(s) it has encountered and exists with a 1.
The script is triggered when we run git commit and will only allow that to proceed if our hook script completes without error. If our pre-commit hook exits with a 0, our the git commit proceeds as normal. If one of the error conditions is met however, it prints it’s messages and it prevent our commit from running.
This is great for helping me to keep the repo contents in sync.
Setting up the hook
In principle, setting up the hook is pretty straightforward, but there are some gotchas to be aware of. Every git repo has a ‘.git/hooks’ directory. For a pre-commit hook, you just need an executable script called pre-commit in that directory. Job done. The script can be any language that your system can execute on the command line and I guess – though I confess, I’ve never tried it – that it could even be a binary.
Since these sort of hooks only execute client-side (that is on the client) the ‘.git/hooks’ directory is not actually part of the repo, so it gets no version control of its contents and its contents are not stored in the repo when others clone it. For these reasons, I like to keep my hooks in the repository itself and create links to them from the ‘.git/hooks’ directory. So in this example, I’d run something like:
ln -s ../../pre-commit.sh .git/hooks/pre-commit
This way, the pre-commit.sh script can be kept in version control in the root of the repo, which also makes them accessible to others with whom we might be collaborating.
I thought you said you were writing this in R?
I do 95% of my spare time tech projects on a Linux server, which I access with a Chromebook. In this case, the Linux server is where the code changes and so on happen and it’s also where our pre-commit hook runs. Everything runs fine there.
The other 5% I do on my aging MacBook Air (and I’m lucky enough to have a really nice MacBook Pro for work stuff). I won’t bore you with the details, but the implementation of stat that ships with Linux is very different to the one that Macs have. This means that the above script fails because the Mac version doesn’t have the -c option.
Bash itself works really well across different platforms, but bash is small and is primarily a glue language that can be used to tie together lots of other command line tools. This can be problematic when implementations of those external tools – like stat here – differ from one platform to another.
For me, working across the different systems for these sorts of projects isn’t completely essential. I could stick to the Linux server, but the fact is that I don’t. So I need a solution that will work wherever I do and for that, we can turn to R.
Rewrite in R
I completely rewrote the initial bash script in R. Again, it’s hopefully not too complicated to read through, even if you don’t know R. The magic here comes from file.mtime() which returns the modification time of the given file.
#!/usr/bin/env Rscript
# make sure that R/sysdata.rda is not out of date
nounfile <- "data-raw/nouns.txt"
adjfile <- "data-raw/adjectives.txt"
sysdatafile <- "R/sysdata.rda"
error_flag <- FALSE
if ( file.mtime(nounfile) > file.mtime(sysdatafile) ){
cat("Error:", nounfile, "is newer than", sysdatafile, "\n")
error_flag <- TRUE
}
if ( file.mtime(adjfile) > file.mtime(sysdatafile) ){
cat("Error:", adjfile, "is newer than", sysdatafile, "\n")
error_flag <- TRUE
}
if ( error_flag ){
cat("Run 'make' in the ./data-raw directory\n")
quit(save = "no", status = 1, runLast = FALSE)
}
While bash is a small glue language that can tie together loads of external utilities (like stat) really well, R is a more fully-featured programming language. This means it’s generally a lot more consistent to use across different platforms. R also works great on the command line, so it’s quick to put together a small script like this.
To make it run, as with the bash version, I keep it in the root of the repo, make it executable with chmod +x pre-commit.R and then create a link to it from .git/hooks/pre-commit.
Let’s see it in action
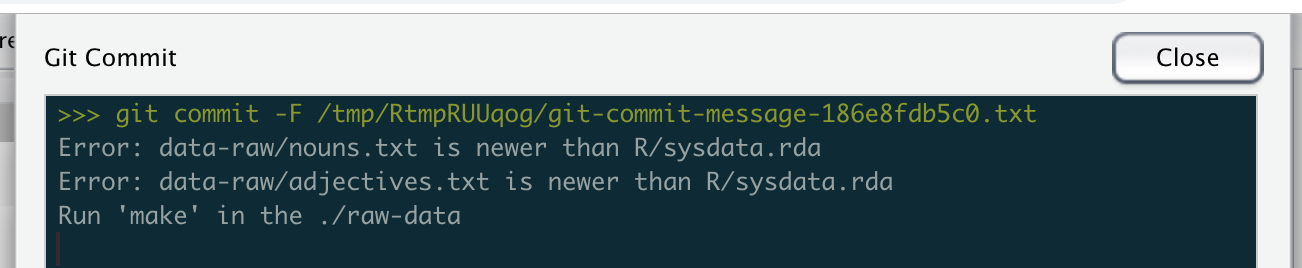
That’s all for now
Hooks are a powerful way to automate actions around your project. Hopefully this post has given you some ideas about how you can get started using them in your projects. Remember, they can be used to do anything that you can code up, in basically any language that will run on your system. R is obviously a great choice here, especially when your main project is in R. If you use them with your R or data project, be sure to let me know about it.
Update! (2018-09-08)
When I posted this article on Twitter, I got a reply from Jim Hester, pointing out that my solution was needlessly complex.
Of course, Jim’s right. For some reason, I’d become hung up on seeing the full error combination. Stopping after the first if() without even running the second seemed wrong somehow. But that’s the fun of programming: the heady mix of human and machine. In this case it doesn’t matter a jot whether the second if() runs if the first one errors. This is because the process to fix that first issue would also fix the second if that was also present. So I’ve taken Jim’s advice to heart and updated my script:
#!/usr/bin/env Rscript
# make sure that R/sysdata.rda is not out of date
nounfile <- "data-raw/nouns.txt"
adjfile <- "data-raw/adjectives.txt"
sysdatafile <- "R/sysdata.rda"
if ( file.mtime(nounfile) > file.mtime(sysdatafile) |
file.mtime(adjfile) > file.mtime(sysdatafile) ){
stop("Source files newer than target\n Run 'make' in ./data-raw")
}
Note that I’ve gone all-in here and combined the two if()s into a single one using a logical OR (|) operator. I guess there’s an argument to be made that this approach is slightly less readable, but I think I’m fine with it for such a tiny use case as the one presented here.