
I don’t generally write much code where R’s performance is a bottleneck, it’s just not what I do. The way I use R is different to many other people and as such I’ve never had to spend much time thinking about the performance of the language.
A few days ago, while reading an article in Quanta, I became interested in the Collatz Conjecture and I wrote up a little function to test how the conjecture plays out.
At around the same time I saw a great Twitter thread from Emily Riederer about performance in R, which really got me thinking.
Despite its simplicity, I knew my Collatz function was fairly slow if I asked it to perform a large number of iterations but I hadn’t thought much of it. I don’t really have much of an R performance mindset and I didn’t have a good mental benchmark of whether my original code was even slow or whether that was just how long I should expect it to take.
When I read Emily’s reply to a comment asking for more information about vector pre-allocation I decided to give it a try to see if I could realise any benefits myself.
The reply in question referred to the on-line version of Colin Gillespie’s Efficient R Programming book which discusses approaches to vector pre-allocation.
Vector pre-allocation was something I had heard about before, but never really dived into. The basic idea is that It’s quicker – much quicker – to write new data into a given position within an existing vector, than it is to append a new value to the end of an existing vector.
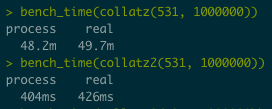
Since my Collatz function was so simple, I decided to try it out and was absolutely blown away by the speed improvement.
Here’s my original function:
collatz <- function(num, iters=100){
count <- 0
output <- c()
while (count < iters){
if ( num%%2 == 0){
num <- num/2
} else {
num <- (num*3)+1
}
count <- count+1
output <- append(output, num)
}
output
}
And here’s the fast version:
collatz2 <- function(num, iters=100){
output <- numeric(iters)
for(i in 1:iters){
if ( num%%2 == 0){
num <- num/2
} else {
num <- (num*3)+1
}
output[i] <- num
}
output
}
Looking at it now, I would say that the first version isn’t idiomatic R at all. It reads more like a straight port from another language into R (which is perhaps not surprising given my background). It doesn’t take any advantage of the way that R handles its data structures and I’m sure there are probably other ways to speed this up too.
If we wanted to represent what the main difference is between the two approaches, it’s that the first starts with an empty vector and for each iteration grows it by one. These examples show ten iterations with a starting value of 13. Here’s what happens inside the un-optimised version:
| Iteration | output vector |
|---|---|
| Initial state | c() |
| 1 | c(40) |
| 2 | c(40, 20) |
| 3 | c(40, 20, 10) |
| 4 | c(40, 20, 10, 5) |
| 5 | c(40, 20, 10, 5, 16) |
| 6 | c(40, 20, 10, 5, 16, 8) |
| 7 | c(40, 20, 10, 5, 16, 8, 4) |
| 8 | c(40, 20, 10, 5, 16, 8, 4, 2) |
| 9 | c(40, 20, 10, 5, 16, 8, 4, 2, 1) |
| 10 | c(40, 20, 10, 5, 16, 8, 4, 2, 1, 4) |
By contrast, the optimised version starts with a full length vector of 0’s and updates them by position for each iteration. Hence the vector is “pre-allocated”, even though it doesn’t yet contain the values that we’d like to return. These values are then populated with each iteration.
| Iteration | output vector |
|---|---|
| Initial state | c(0, 0, 0, 0, 0, 0, 0, 0, 0, 0) |
| 1 | c(40, 0, 0, 0, 0, 0, 0, 0, 0, 0) |
| 2 | c(40, 20, 0, 0, 0, 0, 0, 0, 0, 0) |
| 3 | c(40, 20, 10, 0, 0, 0, 0, 0, 0, 0) |
| 4 | c(40, 20, 10, 5, 0, 0, 0, 0, 0, 0) |
| 5 | c(40, 20, 10, 5, 16, 0, 0, 0, 0, 0) |
| 6 | c(40, 20, 10, 5, 16, 8, 0, 0, 0, 0) |
| 7 | c(40, 20, 10, 5, 16, 8, 4, 0, 0, 0) |
| 8 | c(40, 20, 10, 5, 16, 8, 4, 2, 0, 0) |
| 9 | c(40, 20, 10, 5, 16, 8, 4, 2, 1, 0) |
| 10 | c(40, 20, 10, 5, 16, 8, 4, 2, 1, 4) |
The end result is the same, but the way that we get there makes a massive difference to the performance!
I was extremely happy to be able to increase performance by such a huge amount and finally start to get a handle on the topic of vector pre-allocation. Hopefully this might help some of you too. And if you do spot any other performance improvements I could make, let me know!